Context Windows Don't Tell The Whole Story: What Product Builders Need to Know
Frontier models advertise million-token context windows, but performance degrades well before you hit the limit. Here's what actually works — and how to build AI products that stay sharp.
Every frontier model now advertises a context window measured in hundreds of thousands — sometimes millions — of tokens. It's natural to assume that means you can stuff 200K tokens of context into a prompt and get great results.
You can't. And the gap between advertised capacity and effective performance is wider than most product teams realize.
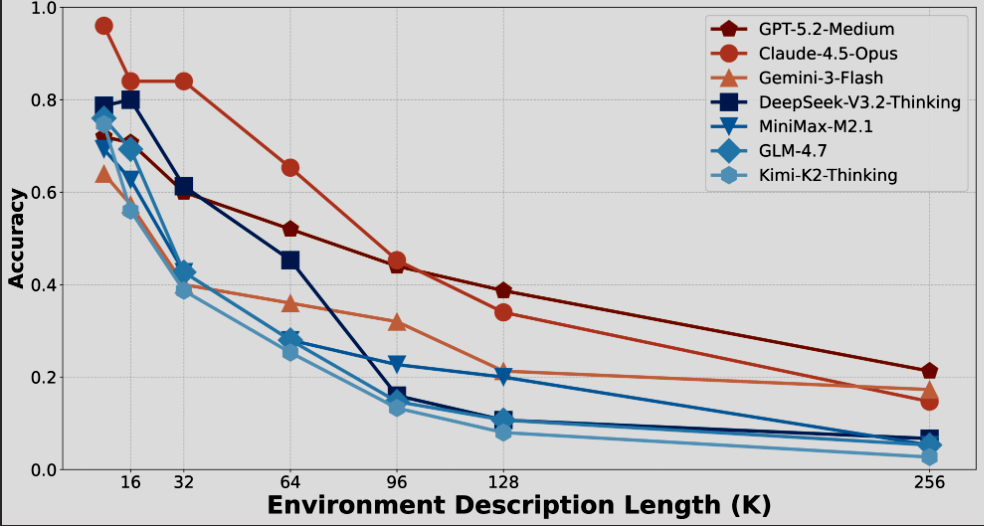
Consider this chart from LOCA-bench [1], a benchmark that measures how well models perform as agents in environments with growing context. Even Claude 4.5 Opus — one of the most capable models available — drops from 96% accuracy at 8K tokens to just 15% at 256K. GPT-5.2-Medium, the most resilient model tested, still falls from 72% to 21%. Every model tested follows the same curve downward.
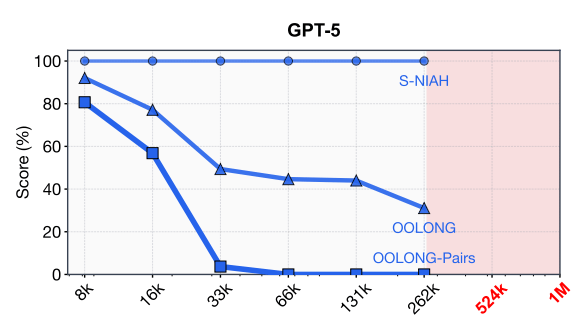
And simple benchmarks actually understate the problem. Research on Recursive Language Models (RLMs) [2] evaluated models on OOLONG, a benchmark where tasks scale in complexity with input length — closer to what real products do. On the pairwise reasoning variant (OOLONG-Pairs), GPT-5 scores just 0.1 at 32K tokens — near zero. On the main OOLONG benchmark, it scores 44.0 at 131K tokens. The standard needle-in-a-haystack test stays near 100% at the same lengths, which is why teams get blindsided — their evals pass but their product doesn't work.
This isn't a bug that will get patched in the next release. It's a fundamental property of how attention mechanisms work at scale — and the more complex the task, the earlier the degradation kicks in. Research from both academic studies and practitioners in production [4] confirms the pattern. If you're building AI products, this is the single most important architectural constraint you need to design around.
The context rot problem
The term "context rot" describes what happens when an LLM's effective reasoning ability decays as its context window fills up. It's not that the model literally can't see tokens beyond position 30K — it's that its ability to reason about them, connect them to the query, and follow instructions in their presence gets progressively worse. As the LOCA-bench results above show, models don't just get slightly worse — they become nearly unusable for agentic tasks at higher context lengths.
Here's what this looks like in practice:
- Instruction drift: System prompts and behavioral guidelines placed at the top of a long context get diluted. The model starts ignoring rules it was following perfectly at 10K tokens.
- Lost in the middle: Information placed in the middle of a long context is retrieved less reliably than information at the beginning or end. This has been well-documented [3] since 2023 and remains an issue.
- Reasoning degradation: Multi-step reasoning chains that work cleanly with focused context fall apart when the model has to sift through noise to find the relevant pieces. The OOLONG results demonstrate this starkly — tasks requiring pairwise reasoning across the context collapse almost immediately as length grows.
- Misleading benchmarks: Standard evaluations like needle-in-a-haystack give models near-perfect scores at lengths where real-world performance has already cratered. If you're only testing retrieval, you'll miss the reasoning degradation entirely.
If your AI product works great in development with short test conversations and falls apart after 20 minutes of real user interaction, this is probably why.
The established playbook (2023–2024)
The good news: the most impactful context management strategies are also the most mature. These have been battle-tested for years and should be your starting point.
RAG and chunking
Retrieval-augmented generation is the foundational context management strategy. Instead of dumping entire documents into a prompt, retrieve specific relevant passages and inject only those. The entire RAG pattern — embedding generation, vector storage, semantic search — is fundamentally a context management technique disguised as a knowledge management one. It became standard practice in 2023 and remains the single most effective way to give models access to large knowledge bases without blowing past the effective reasoning window.
Compaction and conversation management
When context grows too large, summarize it. This is one of the earliest strategies and still one of the most important. Claude Code's auto-compact triggers when context usage gets high (the exact threshold has shifted across versions, from ~75% to as high as 95%). The emerging consensus: compact at 75–85% capacity (not 95%, which risks mid-task disruption), prune tool outputs before summarizing, and maintain external state files that survive compaction. The product design insight: do this transparently — don't make users manage context.
Prompt caching
Prompt caching is now universally available and is the single highest-impact cost optimization for agent workflows. Google pioneered it in May 2024, Anthropic launched in August 2024 (90% cost reduction on cached reads, up to 85% latency reduction), and OpenAI followed in October 2024 with a fully automatic system requiring zero code changes (50–90% cost reduction). For products where system prompts, tool definitions, and conversation prefixes repeat across turns — which is every multi-turn agent — caching is free money. It also has a subtle quality benefit: the model processes your system prompt once at full attention rather than re-reading it through an increasingly noisy window.
Text over screenshots
Browser automation via MCP loads 13,000–17,000 tokens at session start, and after 15 steps of interaction, page state hits 60,000–80,000 tokens. One test of Computer Use to save a single recipe cost $1.27. CLI tools sidestep all of this — a successful operation returns "Done" (6 characters), not a screenshot. Playwright CLI uses ~4× fewer tokens than Playwright MCP; Vercel's agent-browser CLI reduces context by up to 93%. The insight: keep state external and return only minimal confirmations.
If you're building AI products and not doing these already, start here. They're proven, widely adopted, and deliver the biggest bang for the buck.
Infrastructure under the hood (2024–2025)
While application-level strategies get the headlines, infrastructure innovations have quietly made every token cheaper and faster to process — which changes the economics of context management.
KV-cache management addresses a fundamental memory bottleneck: a single 128K-token prompt on Llama 3.1-70B consumes ~40GB of HBM just for KV cache. vLLM's PagedAttention treats GPU memory like OS virtual memory pages, reducing fragmentation from ~70% to under 4% and enabling up to 24× higher throughput. At the routing level, KV-cache-aware request routing achieves 87% cache hit rates and 88% faster time-to-first-token.
Prompt compression offers a different angle. Microsoft Research's LLMLingua achieves up to 20× compression with as little as a 1.5-point performance drop on GSM8K, using a small model's perplexity as a compression signal. It's integrated into LangChain and LlamaIndex. This is particularly useful for RAG pipelines where retrieved documents can be compressed before injection.
MoE architectures drove per-token costs to the floor. Over 60% of open-source model releases in 2025 used Mixture of Experts. DeepSeek-V3/R1 activates only 37B of 671B parameters (5.5% activation). Combined with new hardware, this drove token costs to 5¢ per million — a 4× improvement over the previous generation.
Extended thinking adds another dimension — though the implementations differ more than you'd expect. Claude's <thinking> blocks are automatically stripped from multi-turn context: the model reasons deeply on the current turn, but previous turns' thinking doesn't accumulate in the conversation window. This is genuine context management at the model level — deep reasoning without permanent window cost. OpenAI's o-series reasoning tokens work differently: they're hidden from the developer but still consume context budget during generation, and in multi-turn tool-use flows, reasoning items often need to be re-injected across turns rather than discarded. The product builder's takeaway: extended thinking can reduce context pressure, but how much depends on the provider — check whether reasoning tokens are stripped across turns or just hidden within them.
The infrastructure story matters for product builders because it changes the calculus. Prompt caching means your repeated context is nearly free. Compression means your RAG pipeline can retrieve more aggressively. Lower per-token costs mean you can afford the extra calls that sub-agent architectures require. The application-level strategies and the infrastructure-level optimizations reinforce each other.
Sub-agents and smarter retrieval (2025)
Two patterns matured through 2025 and are now considered best practice: decomposing work across focused sub-agents, and using layered retrieval to find precisely the right context.
Sub-agent architectures
2025 was the year sub-agents went mainstream. Claude Code, Codex, and Devin all converged on the same pattern: don't give one agent a massive context. Spawn focused sub-agents with narrow, relevant context. Each stays well within the effective reasoning window. The orchestrator synthesizes results. This is the architectural equivalent of the Unix philosophy — small, focused tools composed together.
Smarter retrieval, not bigger windows
AI coding agents — the most context-hungry category — converged on layered retrieval strategies to avoid drowning in irrelevant code. Fast text search (ripgrep), structural search (ast-grep on syntax trees), and semantic search (custom embeddings trained on what developers actually need) work together to find the right 2K tokens instead of dumping 50K tokens of "maybe relevant" files.
Aider's approach is particularly elegant: a repository map built with tree-sitter that extracts symbol definitions, constructs a dependency graph, and ranks elements with PageRank. Only files being edited appear in full; everything else is a compact map. As its creator noted: "Counterintuitively, spending a few thousand tokens on this context upfront saves tens of thousands later."
This is the universal lesson. Whether you're building a coding agent, a support bot, or a document analyzer: invest in finding the right context rather than loading all the context.
The tool definition crisis (late 2025 – early 2026)
This is where the story shifts from established patterns to newer innovations that are still maturing. The tool definition problem forced the most dramatic rethinking of context management to date — and the solutions are still evolving.
A typical MCP tool definition consumes 200–500 tokens. Seems manageable. But real products don't have one tool. A five-server MCP setup — GitHub, Slack, Sentry, Grafana, Splunk — consumed roughly 55,000 tokens in tool definitions alone. One practitioner reported 134,000 tokens burned by tool schemas before any user message was sent. At that point, you've already blown past the effective reasoning window and the conversation hasn't started.
Tool Search (November 2025)
One of the first responses to the crisis was Anthropic's Tool Search Tool: mark tools with defer_loading: true, and they remain discoverable but don't consume context upfront. The agent sees only the search tool (~500 tokens) plus non-deferred tools. When it needs a capability, it searches the catalog and gets 3–5 relevant references that expand into full definitions.
Results: context dropped from ~77,000 tokens to ~8,700 — an 85% reduction — while accuracy actually improved. Claude Opus 4 went from 49% to 74% on MCP evaluations. As Simon Willison put it: "context pollution is why I rarely used MCP — now that it's solved there's no reason not to hook up dozens or even hundreds of MCPs."
Code Mode (September 2025 → February 2026)
Cloudflare pioneered a more radical approach. In September 2025, Kenton Varda and Sunil Pai published Code Mode — built on a simple insight: LLMs have trained on millions of TypeScript projects but only a handful of contrived tool-calling examples. Instead of describing each tool as a JSON schema, Code Mode wraps all tools into a typed TypeScript SDK and lets the model write code against it. Initial results: 30–81% token savings depending on task complexity.
Then came the real leap. In February 2026, Cloudflare shipped server-side Code Mode: a single MCP server covering their entire 2,500+ endpoint API using just two tools — search() and execute(). Fixed footprint: ~1,000 tokens, regardless of API surface area. That's down from 1.17 million tokens for the native approach. A 99.9% reduction.
Anthropic arrived at the same insight independently. Their Programmatic Tool Calling approach presents MCP servers as file trees of TypeScript modules rather than tool lists. Token usage dropped from 150,000 to 2,000 tokens — a 98.7% reduction. Internal testing showed average token usage dropping from 43,588 to 27,297 on complex research tasks, with accuracy improving across benchmarks. Less context, better results. That's the theme.
The meta-tools convergence
A complementary approach using GraphQL achieved 70–80% reduction by consolidating data layers into two MCP tools (get_graphql_schema and execute_graphql_query), fetching only requested fields instead of REST's over-fetching.
Speakeasy's Dynamic Toolsets use three meta-tools with lazy schema loading, achieving up to 160× token reduction with 100% task success rates across 40–400 tool toolsets. Stacklok's ToolHive MCP Optimizer hit ~80% input token reduction with 94% selection accuracy and 98% retrieval accuracy across 2,792 tools — outperforming Anthropic's own BM25 and regex search modes. Stainless takes the same approach: three meta-tools (list_api_endpoints, get_api_endpoint_schema, invoke_api_endpoint) instead of one tool per endpoint.
These approaches are converging on a clear consensus — the answer to tool bloat is meta-tools and lazy loading, not bigger context windows — but adoption is still early. Most production systems haven't made the switch yet, and the tooling is evolving fast.
Context budgeting as architecture (early 2026)
Context budgeting is the newest named pattern in this space — only months old as a deliberate practice, though the intuition behind it has been building for over a year. The idea: treat your context window like a budget where every token has a cost measured not in dollars, but in reasoning quality.
Cursor's Dynamic Context Discovery (January 2026) codified five techniques that collectively reduced agent tokens by nearly half. The most impactful: MCP tool lazy loading, where only tool names are in the prompt while full descriptions load on demand. An A/B test showed this reduced total agent tokens by 46.9% for runs using MCP tools. Other techniques: writing long tool responses to files instead of truncating them (the agent reads selectively), saving full chat history as files during summarization (enabling recovery of compressed details), and syncing terminal sessions to the filesystem for grepable output.
Claude Code takes a structured approach. A typical session allocates tokens across system prompt (~2.7K), tools (~16.8K), custom agents (~1.3K), memory files (~7.4K), skills (~1K), and an auto-compact buffer (~33K) — with the remainder for actual conversation. The /context command shows real-time consumption. Custom hooks preprocess data before it enters context: "Instead of Claude reading a 10,000-line log file to find errors, a hook can grep for ERROR and return only matching lines, reducing context from tens of thousands of tokens to hundreds."
An emerging pattern across all these tools is context configuration files — CLAUDE.md, .cursorrules, AGENTS.md. Early research found these files associated with a 28.6% reduction in median runtime and 16.6% reduction in output tokens (Lulla et al., 2026) [5]. These files are essentially curated, pre-compressed context: instead of the agent discovering your conventions by reading code, you tell it upfront in a few hundred tokens.
It's still early days for context budgeting as a formal discipline. But the teams getting the best results from AI are already the ones who obsess over what goes in the window and what stays out.
How coding agents actually manage context
The patterns above aren't theoretical — they're implemented in production tools used by millions of developers. Claude Code is the most transparent example (its architecture is extensively documented), and examining its techniques reveals how the abstract principles translate into concrete engineering.
The compaction pipeline is not just "summarize"
Claude Code's auto-compaction isn't a single summarization call. It's a multi-stage pipeline: first, prune tool outputs — the raw terminal output, file contents, and search results that are the highest-volume, lowest-value content in context. Then summarize the remaining conversation history, preserving recent reasoning and the system prompt. This priority order is validated by the JetBrains research cited above: observation masking (dropping tool outputs while keeping reasoning) matched summarization's effectiveness at lower cost. The insight is that what you compress matters more than how you compress it.
Context configuration files as collaborative context engineering
CLAUDE.md, AGENTS.md, and .cursorrules represent a shift in who does the compression work. Instead of the agent spending tokens discovering project conventions by reading dozens of source files — a 10K+ token exploration — a 500-token configuration file encodes the same information upfront. It's collaborative context engineering: the human curates knowledge about conventions, architecture, and constraints; the agent reasons with that knowledge already loaded. The Lulla et al. data [5] suggests this tradeoff is significant — 28.6% less runtime and 16.6% fewer output tokens across repositories that adopt the pattern.
Sub-agent spawning as context isolation
Claude Code's Task tool spawns a focused sub-agent with a specific prompt and only the relevant files. The parent agent never sees the sub-agent's full working context — just the returned result. This is the sub-agent pattern from the earlier section, but the implementation detail matters: the sub-agent's context is completely isolated, so a 50K-token exploration of a codebase module produces a 500-token summary that enters the parent's window. Codex and Gemini CLI converged on the same architecture. The pattern works because most tasks decompose into a coordination problem (small context, complex reasoning) and multiple execution problems (large context, focused reasoning).
The "write to file, read selectively" pattern
Instead of truncating a 10K-line log to 500 lines — losing 95% of information — write the full output to a file and let the agent grep, head, or read specific sections on demand. The information is preserved while the context window stays clean. This is the filesystem-as-memory pattern: it converts ephemeral context into durable, randomly-accessible state. Both Claude Code and Cursor implement this. Cursor's implementation is particularly instructive — saving full chat history as files during summarization enables recovery of compressed details without keeping them in the window.
Hooks as context preprocessing
Custom hooks run shell commands before tool output enters context. A build step that produces 5,000 lines of webpack output can be preprocessed by a hook that extracts only warnings and the final bundle stats — what would have been 20K+ tokens of noise becomes a 200-token summary before the model ever sees it. This is the same principle as Runtype's transform-data step: reshape data before it reaches the model. The preprocessing happens outside the context window entirely, which means the savings compound — the model never sees the noise, so it never has to reason past it.
These techniques aren't independent. In a well-configured session, hooks preprocess data before it enters context, configuration files eliminate discovery overhead, sub-agents isolate exploratory work, file-based memory preserves information without window cost, and multi-stage compaction handles what remains. The result is an agent that stays well within the effective reasoning window even on tasks that touch hundreds of files across hours of work.
The frontier: when agents run for hours (2025–2026)
The most experimental context management lessons come from pushing agents to their absolute limits — running them for hours or days on complex tasks. These findings are fascinating, but treat them as early signals rather than established best practices.
The GLM-5 Game Boy Advance demo (February 2026) is the most extreme test case. A 744-billion-parameter model built a GBA emulator from scratch in JavaScript, running for 24+ consecutive hours in "zero reference" mode with no existing code or web search. The key architectural insight: "anything not in a file doesn't exist after a context switch." The team implemented an "analyze, build, document" loop where the agent explicitly handed off context to its future self at every context boundary — logging progress, attempt counts, and architectural decisions to files. Without this, the agent would circle without progress across sessions and have no way to detect it.
A JetBrains/NeurIPS 2025 study ("The Complexity Trap") found a surprising result when comparing context management strategies: observation masking — replacing old tool outputs with placeholders while keeping reasoning intact — matched LLM summarization's solve rate while costing significantly less, questioning whether complex summarization is worth the overhead. Summarization risks information loss and adds cost for the summarization call itself. This is an early research finding that challenges the conventional wisdom of "summarize everything" — sometimes the best compaction strategy is "keep the reasoning, drop the raw data."
Perhaps the most fascinating — and least understood — finding comes from Cognition Labs (Devin). They surfaced an unexpected phenomenon: "context anxiety." Claude Sonnet 4.5 was the first model they observed that appeared aware of its own context window, proactively summarizing and taking shortcuts as it approached limits — even with plenty of room remaining. Cognition had to prompt "pretty aggressively" to prevent premature task wrap-up. Nobody fully understands this behavior yet, but it suggests that models are being trained with context-window awareness that, while generally helpful, can hurt performance in well-managed long-running sessions.
The lesson for product builders: if your agent handles long sessions, you need to think about memory as a first-class architectural layer, not just a prompt engineering trick. External state, explicit handoff protocols, and careful compaction timing are the difference between an agent that works for 5 minutes and one that works for 5 hours. In practice, this means configuring hard limits — maximum turns, cost budgets, and reflection checkpoints — so the agent wraps up gracefully rather than degrading silently.
What this means for product builders
If you're building an AI product, you need a context management strategy. Not eventually. Now. Here's the practical framework.
1. Keep conversations focused
The simplest and most effective strategy: don't let context grow unbounded. For chat-based products, this means:
- Set conversation boundaries. Guide users toward starting new conversations for new topics rather than running a single thread for hours.
- Summarize aggressively. After N turns, compress the conversation history into a summary and start fresh context with it. The user doesn't notice; the model performs dramatically better.
- Separate concerns. If your agent handles both customer support and order management, those are two agents with two contexts — not one agent juggling everything.
2. Be surgical with context injection
Every token you put into context should earn its place. Common mistakes:
- Dumping entire documents when the user's question only relates to one section. Use RAG or chunking to extract the relevant passage.
- Loading all tool definitions when only 2-3 are relevant to the current turn. Use dynamic tool selection.
- Including full conversation history when most of it is small talk or resolved questions. Summarize or window it.
3. Design for sub-agent delegation
Complex tasks should be broken into focused sub-tasks, each handled by an agent with minimal, relevant context.
A product recommendation agent doesn't need the user's full conversation history to look up inventory. Give it the product query and the inventory API. That's it. The orchestrating agent handles the conversational context; the specialist agents handle their domains.
4. Use the right model for the right task
Not every sub-task needs a frontier model with a 200K context window. A focused extraction task with 2K tokens of context can run on a smaller, faster, cheaper model with better results than running it on a frontier model with 50K tokens of accumulated conversation.
Putting it into practice with Runtype
The strategies above aren't theoretical — they map directly to Runtype's architecture. Here's how to apply each one concretely.
Flows: control exactly what context each model sees
A Runtype flow separates context preparation from model invocation. Context steps (fetch-url, api-call, transform-data, vector-search, crawl, and 15+ others) gather and reshape data without touching a model. Prompt steps invoke models. Each prompt step only receives the variables it explicitly references through {{templates}} — not everything that's accumulated.
Here's what this looks like in practice:
{{raw_page}}10K tokens of HTML
{{extracted_data}}JavaScript filters to 200 tokens of JSON
{{analysis}}Focused analysis on small, clean context
{{final_output}}References only {{analysis}}, never sees raw HTML
Step 4's prompt template might reference {{analysis}} and {{_record.metadata.customerName}} — that's all it sees. The 10K tokens of raw HTML from step 1 never enter its context. This is the article's thesis in action: invest in finding the right context rather than loading all the context.
The transform-data step is particularly powerful here. It runs JavaScript between steps to extract, filter, and reshape data — turning a bloated API response into precisely the fields the model needs. This is "be surgical with context injection" as a first-class primitive.
Sub-agent delegation: focused context per specialist
Runtype agents support two delegation patterns:
Agent capabilities. Register sub-agents as tools on a parent agent. Each sub-agent has its own system prompt, model, and tools — its own focused context. The parent conversational agent delegates a product lookup, and the sub-agent receives the query plus the inventory API. That's it. No conversation history, no unrelated tool definitions.
Flow-as-tool. Prompt steps can invoke other flows as tools, passing only specific parameters via parameter mapping. A customer support agent can trigger an "order lookup" flow that receives just the order ID — not the 30-turn conversation that led to the question.
Both patterns keep each specialist well within the effective reasoning window while the orchestrating agent manages the broader conversational context.
Records: structured context, not raw text dumps
Instead of stuffing customer information into a system prompt as paragraphs of text, use Runtype's records system with template variables for precise field access:
{{_record.metadata.customerTier}}{{_record.metadata.recentOrders}}{{_record.metadata.openTicketCount}}Each record carries structured JSONB metadata. Your prompt templates reference exactly the fields they need. The model sees Premium and 3 instead of a wall of unstructured customer data competing for attention in the context window.
Vector search: retrieve, don't dump
For document-heavy use cases, Runtype has built-in flow steps for RAG:
generate-embeddingconverts text to vectorsstore-vectorpersists them (Cloudflare Vectorize or Weaviate)vector-searchretrieves semantically relevant passages
Wire these into a flow and the model receives the 3 most relevant paragraphs from your knowledge base — not the entire document. This is the RAG pattern from earlier in this article, implemented as composable flow steps rather than separate infrastructure.
Model routing: right model, right task, right context
Each prompt step in a flow can use a different model. This isn't just cost optimization — it's context management:
- Use a fast model (Haiku, GPT-4o Mini) for extraction and data cleanup on large inputs
- Use a frontier model (Sonnet, GPT-4o) for reasoning on the clean, focused output
- Use embedding models for retrieval steps
The extraction model processes 5K tokens of noisy input and produces 200 tokens of clean output. The reasoning model works with those 200 tokens. Both stay well within their effective reasoning windows.
Agent loops: guardrails for long-running sessions
For agents that run multi-turn conversations, Runtype provides hard limits that prevent context degradation:
maxTurnscaps iteration count (1–100) so agents wrap up rather than degrademaxCostsets a dollar budget — the agent finishes gracefully when approaching it- Reflection intervals trigger the agent to reassess its approach at configurable checkpoints
These aren't afterthoughts — they're the "careful compaction timing" the research above demands. An agent that knows when to stop produces better results than one that pushes through an overloaded context window.
Evals: measure whether your strategy works
Here's the part most teams skip. Runtype's Product Evals let you run the same flow with different configurations and compare results:
- Swap models per step via
stepOverrides— does Sonnet outperform GPT-4o on your specific prompts? - Adjust temperature and response formats per step
- Use virtual records to test different input scenarios without storing test data
- Compare cost, latency, token usage, and success rate across configurations
The question you're answering: does a smaller, faster model with focused context outperform a frontier model with accumulated conversation? For your specific use case, with your specific data, the answer might surprise you. Measure it instead of guessing.
Dispatch API: programmatic orchestration
Everything above is accessible via the Dispatch API — a single endpoint for executing flows, agents, and ad-hoc configurations programmatically. You can define inline flows, pass runtime tools, configure step overrides, and stream SSE results. This is how you compose the patterns above from your own application code rather than relying solely on the dashboard UI.
Code Mode: give agents your entire API in ~200 tokens
The tool definition crisis described earlier isn't just a problem Runtype helps you work around — it's one we've solved at the platform level. Following the approach Cloudflare pioneered, Runtype's API supports Code Mode: instead of loading dozens of tool definitions into context, agents interact with Runtype through a typed SDK exposed via just two MCP tools — search() and execute(). The search tool lets agents explore the full API spec at runtime without network calls. The execute tool runs JavaScript against the live API with authentication handled transparently.
The standard Runtype MCP server exposes 44 tools — roughly 15,000 tokens of definitions before a single message is sent. Code Mode drops that to ~200 tokens. The full Runtype API surface — agents, flows, tools, records, schedules, evals — remains fully discoverable on demand without upfront context cost.
For orchestrating agents that manage Runtype resources alongside other tools, this is the difference between a tool budget that's mostly spent before the conversation starts and one that's practically empty. Combined with Runtype's own context management primitives — flows that isolate context per step, sub-agent delegation, and transform-data preprocessing — context efficiency compounds at every layer of the stack.
The stack, not the silver bullet
The token efficiency revolution isn't a single innovation. It's a stack of interlocking improvements, each compounding the others:
- Protocol layer: MCP standardization and Code Mode collapsed tool definition overhead by 99%+
- Discovery layer: Dynamic tool search eliminated context pollution from unused tools
- Application layer: Semantic search, AST-aware retrieval, and repository maps ensure agents read only what matters
- Session layer: Context compaction and hierarchical memory let agents work indefinitely without context exhaustion
- Interface layer: CLI-first architectures proved that text beats screenshots by an order of magnitude
- Infrastructure layer: Prompt caching, KV-cache optimization, and MoE architectures made every remaining token cheaper
An agent workflow that consumed hundreds of thousands of tokens 18 months ago might now use a few thousand — while being more accurate.
The most significant insight from this period may be Cursor's principle of dynamic context discovery: "provide fewer details up front, let the agent pull relevant context on its own." The most token-efficient prompt isn't the most compressed one. It's the one that loads nothing until it's needed.
That's the design principle worth internalizing. Not "how do I fit more into my context window?" but "how do I keep my context window almost empty, and let the agent fill it with exactly what it needs?"
The teams building the best AI products in 2026 aren't the ones with the longest context windows. They're the ones who figured out that the art is in what you don't put in the prompt.
References
- Weihao Zeng, Yuzhen Huang, and Junxian He. "LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth." arXiv preprint arXiv:2602.07962, 2026. https://arxiv.org/abs/2602.07962
- Alex L. Zhang, Tim Kraska, and Omar Khattab. "Recursive Language Models." arXiv preprint arXiv:2512.24601, 2025. https://arxiv.org/abs/2512.24601
- Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. "Lost in the Middle: How Language Models Use Long Contexts." Transactions of the Association for Computational Linguistics, 2024. https://arxiv.org/abs/2307.03172
- Hasan S. Ali. "Context Rot: The Emerging Challenge for Long-Running AI Agents." Understanding AI, 2025. https://www.understandingai.org/p/context-rot-the-emerging-challenge
- Lulla et al. "Codified Context: How AGENTS.md Files Shape AI-Assisted Software Engineering." arXiv preprint arXiv:2601.20404, 2026. https://arxiv.org/abs/2601.20404